What Is Happy Horse 1.0?
The open-source AI video generation model that topped the AI Video Arena.
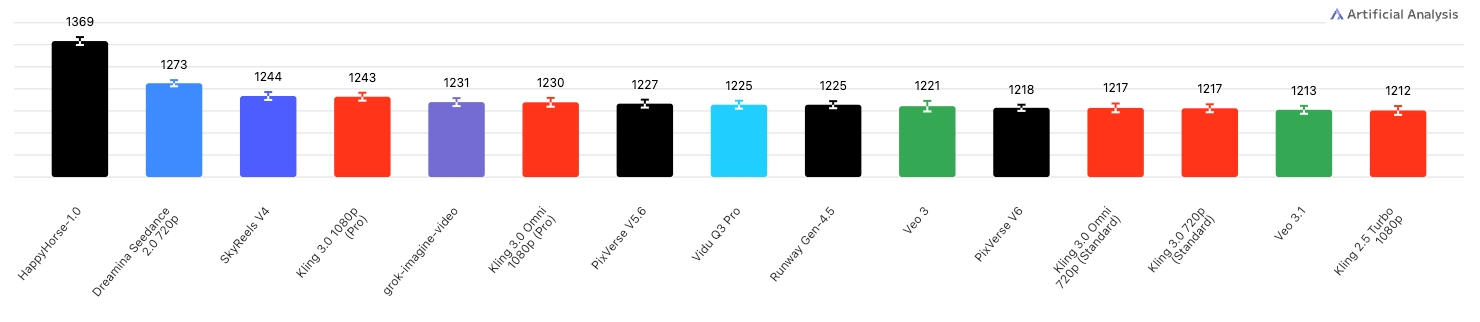
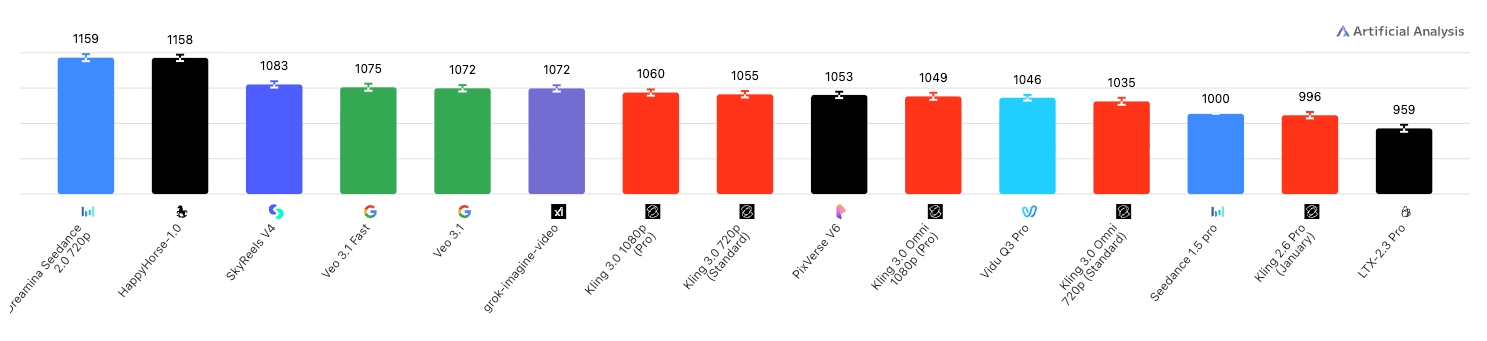
Happy Horse 1.0 is a 15B-parameter unified Transformer model that jointly generates video and synchronized audio from text or image prompts. Released in early 2026, it achieved the #1 ranking on the Artificial Analysis AI Video Arena with an Elo score of 1333, surpassing Seedance 2.0 and other leading models in blind human evaluations.
Key Specifications
| Parameters | 15B |
| Architecture | 40-layer Unified Single-Stream Transformer |
| Distillation | DMD-2 8-step distillation (no CFG) |
| Compiler | MagiCompiler full-graph compilation (~1.2x speedup) |
| Inputs | Text, Image |
| Outputs | Video, Synchronized Audio |
| Resolution | 1080p (16:9, 9:16) |
| Duration | 5-8 seconds |
| Lip-Sync Languages | English, Mandarin, Cantonese, Japanese, Korean, German, French |
| Hardware | NVIDIA H100 or A100 (≥48GB VRAM), FP8 quantization supported |
| License | Open Source (Commercial Use) |
Core Capabilities
Unified Transformer
40-layer self-attention network with 4 modality-specific layers on each end and 32 shared layers — single-stream processing with per-head gating for stable training.
Joint Video + Audio
Generates synchronized dialogue, ambient sound, and Foley alongside video frames — no post-production dubbing required.
8-Step DMD-2 Distillation
Reduces denoising to just 8 steps without classifier-free guidance, accelerated further by the in-house MagiCompiler runtime.
Multilingual Lip-Sync
Native support for 7 languages with industry-leading low Word Error Rate (14.6%).
1080p Output
5-8 second clips at 1080p in standard aspect ratios (16:9, 9:16) — suitable for social, advertising, and cinematic use cases.
Open & Self-Hostable
Base model, distilled model, super-resolution module, and inference code released openly with commercial-use permission.
Arena Elo Rankings
Elo scores from the Artificial Analysis AI Video Arena (April 8, 2026).
Text-to-Video
Text-to-Video with Audio
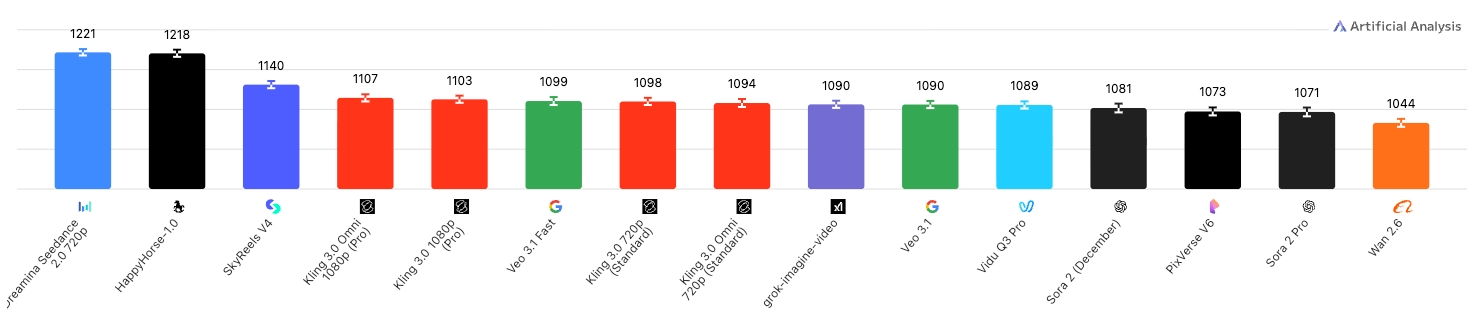
Image-to-Video
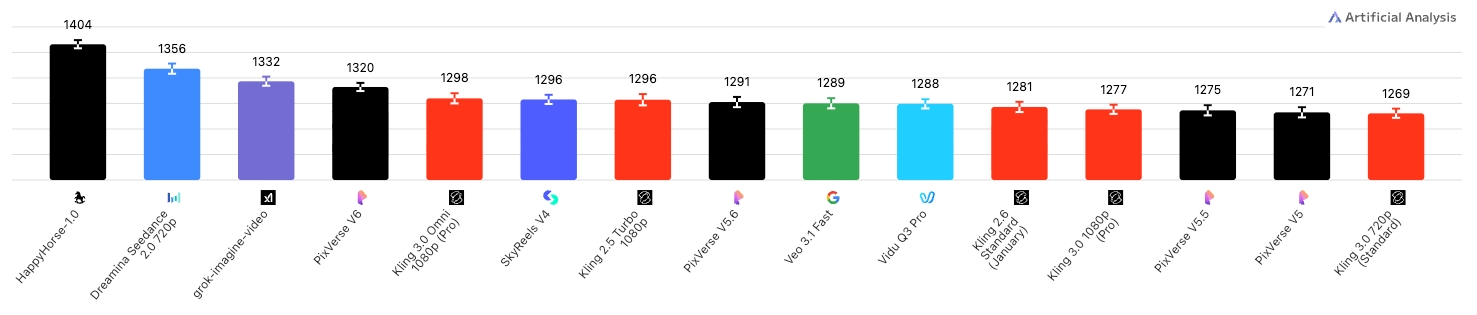
Image-to-Video with Audio
Known Limitations
Based on community testing and independent evaluations.
- Best at single-character portrait scenarios; quality drops with multiple people or complex scenes
- Requires H100/A100 GPU (≥48GB VRAM); consumer GPUs cannot run it currently
- Generation length limited to ~10 seconds before quality degrades
- High-definition output still benefits from super-resolution post-processing
- Community quantization solutions are in progress but not yet mature for local deployment